Haven't I seen this before?
These are the visual aids for my zip bomb talk at WOOT 2019.
I made a recording of the screen and audio capture using the laptop mic. I messed up the screen capture a bit, cutting off the right and bottom sides of the screen. At the bottom of the screen I originally had a terminal with the real-time extraction of one of the zip bombs going on throughout the whole talk. Because that was cut off in the screen recording, I re-recorded the terminal output later and composited it onto the original video.
Alex Gantman: All right, let's move on with our next session, "A Town Called Malice," and I hope you're all by the way appreciating the effort we put into picking session names.
Our first talk of the session is from David Fifield on a better zip bomb. You can download David's slides as a zip file from the USENIX web site. [laughter]
This is also the winner of the best paper award, as you heard yesterday. [applause]
This is also one of the papers that went through the artifact evaluation and passed the artifact evaluation, so you can download the better zip bomb.
All right, let's everybody welcome David.
David Fifield: Thank you. Before anything else, I would like to start a process running. I always judge the quality of a talk by how long it takes for the first terminal window to appear, so, here we go.
I'm here in the source code. If you download the artifact, this is actually part of what you'll get. And I'm going to say, "make zblg.zip". And run this. "zblg" stands for "zip bomb, large." Now that took about 10 seconds and what it gave us was a file of about 10 megabytes. How long could it take to unzip a 10-megabyte zip file? Well, let's find out. So, I'm going to run an unzip command here, and I'm going to use this "-p" option. "-p" just means "unzip to standard output." I'm not actually going to be writing to disk. So we're going to be unzipping this entire file to standard output and I'm also going to pipe it into a "dd" command here, and that's just for monitoring. It's going to give us information on how much progress the unzipping is making. I'm going to give it a generous block size, so we're not bound in I/O—in kernel system calls and say "progress=status", that will give us status messages, and we're just going to write to /dev/null. All right, is that—everything look on board here? And... sorry. "status=progress". What would it be without a botched demo? All right, so we've started this zip bomb unzipping. We're already one gigabyte in... and 2.4 gigabytes at 10 seconds. And you know what, we're just going to kinda shrink this down and keep this in the corner and keep an eye on it. Is that visible? All right.
https://www.bamsoftware.com/hacks/zipbomb/ (paper and code)
https://www.bamsoftware.com/talks/woot19-zipbomb/ (this talk)
So my name is David Fifield and I'm going to present to you a new type of zip bomb that I invented and explain some ideas about how it works. There are a couple hyperlinks here. The top one is an HTML version of this WOOT paper, somewhat expanded, with links to source code and things like that. The second link here is this very talk, if you want to later click on some hyperlinks or things like that, or work your way through some of the examples that I'll show. They'll be at that link.
$ git clone https://www.bamsoftware.com/git/zipbomb.git $ cd zipbomb $ make $ sha256sum zbsm.zip zblg.zip zbxl.zip fb4ff972d21189beec11e05109c4354d0cd6d3b629263d6c950cf8cc3f78bd99 zbsm.zip f1dc920869794df3e258f42f9b99157104cd3f8c14394c1b9d043d6fcda14c0a zblg.zip eafd8f574ea7fd0f345eaa19eae8d0d78d5323c8154592c850a2d78a86817744 zbxl.zip $ wc --bytes zbsm.zip zblg.zip zbxl.zip 42374 zbsm.zip 9893525 zblg.zip 45876952 zbxl.zip $ unzip -l zblg.zip | tail -n 1 281395456244934 65534 files $ ./ratio zblg.zip zblg.zip 281395456244934 / 9893525 28442385.9286689 +74.54 dB $ time unzip -p zblg.zip | dd bs=32M of=/dev/null status=progress ...
And here is just a short description of some of the commands that I've just run, in case you want to do that yourself.
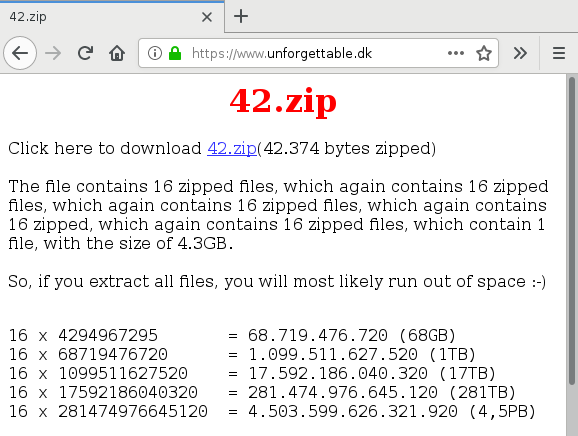
Now, a zip bomb, or compression bomb more generally, is a compressed file that is small, and then when you uncompress, it becomes very very large. If you have heard of zip bombs at all, you have probably heard of this one called 42.zip. And you can download it from this web site here, and the description here is exactly accurate. So 42.zip is a zip file that itself contains 16 zip files, and each of those contains 16 zip files, and so on for a total of about 6 layers and at the very bottom layer, there's a single file in each of the "leaf" zip files that's 4 gigabytes compressed. So, if you uncompress all of those, you do in fact end up with four and a half petabytes of data.
So let's give this one a try. I have here a copy of 42.zip. It's about 42 kilobytes. Let's make a temporary directory here. And unzip 42.zip. Are you all ready for four and half petabytes? If you're squeamish, you may want to avert your eyes, here we go! Oh... That's disappointing. So what do we have here? We have, oh, only half a megabyte in this directory, unzipping this fearsome file 42.zip. What went wrong?
Well, obviously, it's built recursively, and by running that one unzip command we only unzipped the top level of the recursion, and there just isn't any expansion at that level.
The only universally supported compression algorithm is DEFLATE (RFC 1951).
But DEFLATE's maximum compression ratio is 1032.
$ dd if=/dev/zero bs=1000000 count=1000 | gzip > test.gz
$ gzip -l test.gz
compressed uncompressed ratio uncompressed_name
970501 1000000000 99.9% test
$ echo '1000000000 / 970501' | bc -l
1030.39564101428025318881
42.zip's recursive nesting of zip files is an attempt to work around the DEFLATE limitation.
Question: can we get a high compression ratio without using recursion?
Now you may ask, why is 42.zip constructed this way? Why does it use this recursive construction when, as we've just seen, it doesn't actually work, except maybe with very specialized zip parsers? I think that the nested nature of 42.zip is a workaround for the fact that the DEFLATE compression algorithm, which is the algorithm most used with the zip format, just cannot achieve a very dense compression ratio. And in fact, this DEFLATE algorithm, which you find specified in RFC 1951, has an upper bound on its compression ratio of precisely 1032. I don't—I'm not going to explain where that comes from, but if you work your way through the spec and look at some of the constants, you'll see that, oh, you just cannot achieve anything—a compression ratio more dense than 1 in 1032. And not only is that an upper bound, it's also, you can get close to it very easily. For example, if you just gzip a gigabyte of zeroes—and here gzip is different than the zip format but it also uses DEFLATE, so I use it for this example—if you gzip a gigabyte of zeroes you'll end up with a megabyte of zeroes and if you calculate the ratio it's very close to 1032. So this is a hard upper bound—we cannot do better—but we can quite easily get very close to this bound.
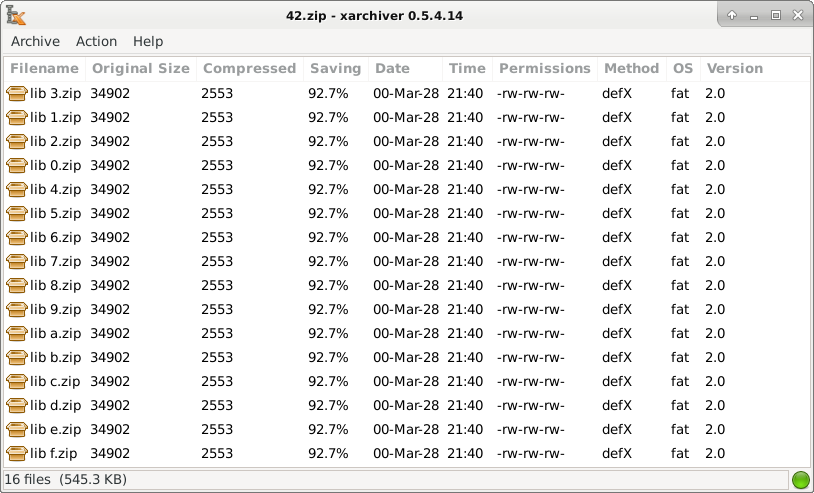
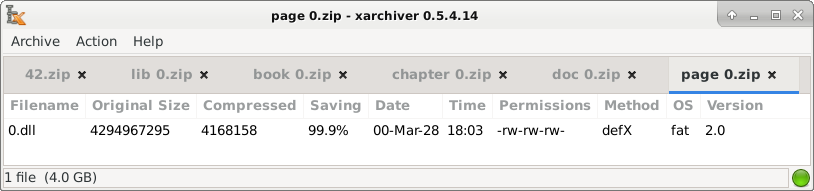
And if we look at 42.zip, this is what it looks like on the inside. It's got these 16 files at the top layer I told you about. And if you click down into those files, it goes through 42.zip, to library, to book, to chapter, to doc, to page, that's the nested nature here, and at the very bottom you have this 0.dll, 4 gigabytes compressed—or sorry—4 gigabytes uncompressed, and notice it's about 4 megabytes compressed. There again is that ratio of about 1032.
So the question is, this is kind of disappointing, that ratio of 1000 isn't really very much, and it's a bummer that this recursive nested structure doesn't actually work. So can we get a high compression ratio without using recursion? And in particular, can we exceed this DEFLATE limit of 1032?
| zbsm.zip | 42 kB | → | 5.5 GB |
| zblg.zip | 10 MB | → | 281 TB |
| zbxl.zip | 46 MB | → | 4.5 PB (Zip64, less compatible) |
The answer to the question is a decided "yes," and we'll get into why that works. For the purposes of this research I produced a few specific output files, this zblg is the one we're working on right now, and you can see here the size of the zip file and then the size of the unzipped file. Now, if we were constrained to the DEFLATE limit, these 10 megabytes could expand to at most 10 gigabytes, and you see down here we passed that limit a long time ago.
So how is this possible? To understand how it's possible... There are about four or five cool ideas in this research, I think. It was just a really fascinating project. And I can't get into all of these cool ideas, so I'm going to focus on the one that I think is most important for you to understand, which is the idea of "quoting" parts of the zip format so that they are treated as both, as data and as code, at different points in the extraction.
![A block diagram of the structure of a zip file. The central directory header consists of three central directory headers labeled CDH[1] (README), CDH[1] (Makefile), and CDH[3] (demo.c). The central directory headers point backwards to three local file headers LFH[1] (README), LFH[2] (Makefile), and LFH[3] (demo.c). Each local file header is joined with file data. The three joined blocks of (local file header, file data) are labeled file 1, file 2, and file 3.](normal.svg)
A zip file consists of a central directory, which is like a table of contents that points backwards to individual files.
Each file consists of a local file header and compressed file data.
The headers in the central directory and in the files contain (redundant) metadata such as the filename.
The zip file format specification is called APPNOTE.TXT. For a specification, it's not very precise. If you read it with a security mindset, you will quickly think of many troubling questions.
So to understand that one key idea, we need to take a little bit of a detour and understand what the zip format looks like. A zip file has a sort of table of contents—it's called the central directory—and it's located at the end of the file. The central directory is made up entries called central directory headers or CDHs, and each one of those contains some file metadata, so for example: a filename, a modification time, a checksum. And then it has a pointer that points backwards to a file entry earlier in the file, and it points to a local file header, or LFH. The local file header contains a redundant copy of most of the same metadata that's stored in the central directory, so for example: filename, modification time, checksum. And then immediately following the local file header is a chunk of compressed file data. And the compression algorithm is almost always DEFLATE.
Now—I got into this whole project after reading the zip file format specification. It's a file called APPNOTE.TXT. And the word "specification" is kind of loose in this case. APPNOTE.TXT is historically an important document, and uh— Didn't think about this. I may need to kill my unzip process before it kills my whole battery. [laughter] We'll get there. This APPNOTE.TXT is a historically important document because it's one of the things that made zip the ubiquitous format it is today. Back in the day, in like the BBS days, people had a need for file compression, and there were a bunch of proprietary, secret programs competing. And zip was the one that published, as I understand it, zip was the one that published a specification allowing interoperability, and that's why zip sort of took over the world. [notification says the battery is empty] Don't worry—there are two batteries in this laptop.
But, this specification, for being a specification, is not very precise, and if you read this, being a security person, within five minutes you'll start asking yourself questions that are underspecified. For example, what if we had two of these central directory headers with the same filename? What happens in that case? What if we had a local file header here or even just some garbage data that was not pointed to by anything in the central directory? Or what if, two of these central directory headers pointed to the same file? All right, so that's the first light bulb moment.
![A block diagram of a zip file with fully overlapping files. The central directory header consists of central directory headers CDH[1], CDH[2], ..., CDH[N−1], CDH[N], with filenames A, B, ..., Y, Z. There is a single local file header LFH[1] with filename A whose file data is a compressed kernel. Every one of the central directory headers points backwards to the same local file header, LFH[1]. The lone file is multiply labeled file 1, file 2, ..., file N−1, file N.](overlap.svg)
Compress one kernel at ratio 1032:1, refer to it many times.
Unfortunately this doesn't quite work, because filenames don't match.
$ unzip overlap.zip
Archive: overlap.zip
inflating: A
B: mismatching "local" filename (A),
continuing with "central" filename version
inflating: B
...
Here's an idea of how we can maybe exceed that DEFLATE limit on compression ratio. Let's build a zip file, but we're only going to put one file in it, and the contents of this file are going to be one very highly compressed chunk of data—we'll call it the "kernel"— and this kernel will be compressed with a ratio very close to that limit of 1032. But the key thing is we're only going to have one copy of that kernel, and then we're going to refer to it many times. So notice how this works. The local file header is about 30 bytes. The central directory header is 46 bytes. Let's say this kernel is 1000 bytes—let's say it's 1 kilobyte and it extracts to 1 megabyte. How much does that—if we have one file—how much does that 1 megabyte of output "cost" us? Well, it "costs" 1 kilobyte for the kernel itself, plus 30 bytes, plus 46 bytes. So that's the cost for the first megabyte. But how much does the second megabyte cost us? Well, we don't need another copy of this local file header. We don't need another copy of the kernel. All we need is another 46 bytes for this central directory header. So now our ratio is 1 megabyte divided by 46 bytes, which is much better than 1032. And the more headers we have pointing to the same file, the better and better that ratio gets. You see how this works?
So this is the first idea, this sort of file format hack. This is really a file format hack talk. If you're into things like JPEGs being interpreted as JavaScript, and all that kind of stuff, this is very much in that same spirit. Now this idea unfortunately doesn't work. It works with some zip parsers but not all. And in particular, the command-line unzip program, Info-ZIP UnZip, will extract a file that looks like this, but it will warn you. It will tell you each time that you have mismatched metadata. So here we have a central directory header with filename "A" pointing to filename "A", that's fine. But here we have a filename "B" pointing to filename "A". There's a mismatch and we get a warning on the command line. And some unzippers will just refuse to process the file. So that's unfortunately an incomplete solution.
![A block diagram of a zip file with quoted local file headers. The central directory header consists of central directory headers CDH[1], CDH[2], ..., CDH[N−1], CDH[N], with filenames A, B, ..., Y, Z. The central directory headers point to corresponding local file headers LFH[1], LFH[2], ..., LFH[N−1], LFH[N] with filenames A, B, ..., Y, Z. The files are drawn and labeled to show that file 1 does not end before file 2 begins; rather file 1 contains file 2, file 2 contains file 3, and so on. There is a small green-colored space between LFH[1] and LFH[2], and between LFH[2] and LFH[3], etc., to stand for quoting the following local file header using an uncompressed DEFLATE block. The file data of the final file, whose local file header is LFH[N] and whose filename is Z, does not contain any other files, only the compressed kernel.](quote.svg)
We need separate local file headers, but we cannot just put them end to end, because the decompressor is expecting a structured DEFLATE stream, not another local file header.
We need a way to protect or quote the local file headers to prevent them from being interpreted as DEFLATE data.
Solution: add a prefix that wraps the local file header in a non-compressed literal block, thus making it a valid part of the DEFLATE stream.
3.2.3. Details of block format Each block of compressed data begins with 3 header bits containing the following data: first bit BFINAL next 2 bits BTYPE BFINAL is set if and only if this is the last block of the data set. BTYPE specifies how the data are compressed, as follows: 00 - no compression 01 - compressed with fixed Huffman codes 10 - compressed with dynamic Huffman codes 11 - reserved (error)
3.2.4. Non-compressed blocks (BTYPE=00)
Any bits of input up to the next byte boundary are ignored.
The rest of the block consists of the following information:
0 1 2 3 4...
+---+---+---+---+================================+
| LEN | NLEN |... LEN bytes of literal data...|
+---+---+---+---+================================+
LEN is the number of data bytes in the block. NLEN is the
one's complement of LEN.
The way we complete the solution—and here is the actual key idea that I want you to understand—we need a way to have separate local file headers. We need them separated because we need distinct filenames, but we cannot simply concatenate them at the beginning of the file. Do you see why? Why we can't just say, local file header 1, local file header 2...? It's because local file header 2 would be treated as DEFLATE data. It would be treated as compressed file data, and it just isn't structured correctly for that. So we need a way to protect that subsequent local file header from being interpreted as raw DEFLATE, as part of the raw DEFLATE stream. Fortunately, DEFLATE, the format, offers a way to do this. So, DEFLATE, to get a little bit deeper here, is a sequence of blocks. And to decompress a stream, you just decompress each block in series. Now, we're used to thinking about compressed blocks, but DEFLATE also offers non-compressed blocks, and it's just keyed with this two-byte [correction: two-bit] field here. "00" means no compression. "01" and "10" mean some form of compression. And what the non-compressed block, it just looks like this. You have a length field, you have a redundant length field, and then you just quote n bytes of data. And I say "quote" because what we're doing is we're taking something that is "code," that has meaning in the zip structure, and we're turning it into something that is just dumb data, we're just turning it into a stream of bytes that will become part of the DEFLATE stream. So, what we have here, these little green colors here, these are those 5-byte non-compressed block headers. So what we're going to have here is a long DEFLATE stream that starts here, and it's going to say, oh, we start with a non-compressed block. And the contents of this non-compressed block happen to look like a zip local file header, but whatever, you know, I'll copy that to the output. And then we run into another one. Oh, another non-compressed block. It also happens to look like a local file header, but whatever, we'll copy it to the output. And you follow it down the chain till finally you get to the kernel and you're like, oh all right, so here's a compressed block, very highly compressed it turns out, and we'll decompress that and then we're done. But every file here is overlapped, you see, and they all share the kernel. That's where we get our effectiveness. We don't need to repeat the bytes of the kernel with its relatively low compression ratio of 1000, 1032.
$ ./zipbomb --alphabet=ABCDE --num-files=5 --compressed-size=50 > test.zip
$ unzip -l test.zip
Archive: test.zip
Length Date Time Name
--------- ---------- ----- ----
36245 1982-10-08 13:37 A
36214 1982-10-08 13:37 B
36183 1982-10-08 13:37 C
36152 1982-10-08 13:37 D
36121 1982-10-08 13:37 E
--------- -------
180915 5 files
| A | B | C | D | E |
|---|---|---|---|---|
BFINAL=0 BTYPE=00 31 bytes "PK\x03\x04\x14\x00..." BFINAL=0 BTYPE=00 31 bytes "PK\x03\x04\x14\x00..." BFINAL=0 BTYPE=00 31 bytes "PK\x03\x04\x14\x00..." BFINAL=0 BTYPE=00 31 bytes "PK\x03\x04\x14\x00..." BFINAL=1 BTYPE=10 compressed kernel 36121 × 'a' |
BFINAL=0 BTYPE=00 31 bytes "PK\x03\x04\x14\x00..." BFINAL=0 BTYPE=00 31 bytes "PK\x03\x04\x14\x00..." BFINAL=0 BTYPE=00 31 bytes "PK\x03\x04\x14\x00..." BFINAL=1 BTYPE=10 compressed kernel 36121 × 'a' |
BFINAL=0 BTYPE=00 31 bytes "PK\x03\x04\x14\x00..." BFINAL=0 BTYPE=00 31 bytes "PK\x03\x04\x14\x00..." BFINAL=1 BTYPE=10 compressed kernel 36121 × 'a' |
BFINAL=0 BTYPE=00 31 bytes "PK\x03\x04\x14\x00..." BFINAL=1 BTYPE=10 compressed kernel 36121 × 'a' |
BFINAL=1 BTYPE=10 compressed kernel 36121 × 'a' |
Local file headers are treated as both code and data: both as part of the zip structure (code) and as part of a DEFLATE stream (file data).
$ unzip test.zip Archive: test.zip inflating: A inflating: B inflating: C inflating: D inflating: E $ xxd E | head -n 5 00000000: 6161 6161 6161 6161 6161 6161 6161 6161 aaaaaaaaaaaaaaaa 00000010: 6161 6161 6161 6161 6161 6161 6161 6161 aaaaaaaaaaaaaaaa 00000020: 6161 6161 6161 6161 6161 6161 6161 6161 aaaaaaaaaaaaaaaa 00000030: 6161 6161 6161 6161 6161 6161 6161 6161 aaaaaaaaaaaaaaaa 00000040: 6161 6161 6161 6161 6161 6161 6161 6161 aaaaaaaaaaaaaaaa $ xxd D | head -n 5 00000000: 504b 0304 1400 0000 0800 a06c 4805 a1b7 PK.........lH... 00000010: f363 3200 0000 198d 0000 0100 0000 4561 .c2...........Ea 00000020: 6161 6161 6161 6161 6161 6161 6161 6161 aaaaaaaaaaaaaaaa 00000030: 6161 6161 6161 6161 6161 6161 6161 6161 aaaaaaaaaaaaaaaa 00000040: 6161 6161 6161 6161 6161 6161 6161 6161 aaaaaaaaaaaaaaaa $ xxd C | head -n 5 00000000: 504b 0304 1400 0000 0800 a06c 4805 29b0 PK.........lH.). 00000010: 790b 5600 0000 388d 0000 0100 0000 4450 y.V...8.......DP 00000020: 4b03 0414 0000 0008 00a0 6c48 05a1 b7f3 K.........lH.... 00000030: 6332 0000 0019 8d00 0001 0000 0045 6161 c2...........Eaa 00000040: 6161 6161 6161 6161 6161 6161 6161 6161 aaaaaaaaaaaaaaaa
Using the source code, this is a quick example of a smaller version of the zip bomb containing just five files. So here, five files, a kernel size of 50 bytes. And if we open up each of these files, let's go all the way to the last file, the final file, file "E" in this case, is just the kernel. So the kernel here, in order to get high compression, it has to have high redundancy. It's just this many copies of the letter 'a'. So that's what's in file "E". Now notice the sizes of these files get bigger by exactly 31 bytes as you get close to the beginning of the file, and that's an artifact of the quoting procedure. So each local file header adds 30 bytes for the header itself, plus 1 byte for the 1-byte filename that we're using. You notice the difference between all of these is 31 bytes. So here, file "D", the output of this is finally the kernel, which is reused from file "E", and we add a non-compressed block that looks like this. And this happens to be the magic number for a zip local file header. These initials here, "PK", those are the initials of Phil Katz, who was the founder of PKWARE, which was the company that made PKZIP and published this specification originally. And the moral of this story is: if you want to achieve immortality, put your initials in a file format somewhere. So again, on to file "C", it's the same as file "D" but with an additional prefix. "B" is the same as "C" with an additional prefix. And "A" is the same as "B" with an additional prefix. So you see, at one point, each of these local file headers is being treated as part of the zip structure, and another point is being treated as part of the actual files contained in the zip. And that's not really what we're going for, we really just wanted the kernel reuse, but this quoting hack is how we achieve that kernel reuse.
And looking at these files, this is the final file "E" that contains only the kernel. It's just full of 'a's. Here's "D", it contains a header, 31-byte header, followed by the kernel. And here's "C", it contains the same thing with an additional header. And actually you can see the filenames stored as part of the header. So file "C" contains the headers for file "D" and file "E".
With proper optimization, the quoted-overlap construction produces output that is quadratic in the input size.

(Now showing some of the additional ideas not covered in this talk.)

All right, so, there are a lot of details that go into optimizing this, now that you have this basic construction, like what's the maximum you can do with a specific size. And it turns out that if you optimize correctly, you get quadratic growth. So the output size of the zip is n2, if n is the input size of the zip. And here's a picture of what that looks like. So, if you don't overlap, all you get is linear growth. And let me explain. This is a log–log plot here, so every little square is a factor of 10. 1 kilobyte, 10 kilobytes, 100 kilobytes, 1 megabyte. And in a log–log plot, if you graph a polynomial, the exponent on the polynomial will be the slope. So you can see if we don't overlap DEFLATE, if we just compress things with that ratio of 1032, we get a slope of 1 which means we have linear growth, n to the first power. But with the quoted DEFLATE construction that I've just shown you, we get a slope of 2, which means every time we increase the input by a factor of 10, we increase the output by a factor of 100, and we get a slope of 2. "zblg" right here is the one we're working on (240 gigabytes in, by the way). And "zbsm" is a smaller one that I made just to match the input size of 42.zip so you can compare it to whether it's being extracted recursively or non-recursively. You notice that it stops right here, it stops at 281 terabytes. That's the output size of zblg.zip. Why 281 terabytes? Well, that happens to be 248 bytes, which it turns out is the absolute maximum you can store in a zip file, without turning on 64-bit extensions.
Speaking of which, I'll show you another graph real quickly, which is the same but with a bunch of added lines. This shows some of the other variants that I talked about, some of the other cool ideas I don't have time for in this talk, but for example you can see that if you activate these 64-bit extensions, Zip64, the sky's the limit. You can make a file as large as you want, you know, even up to over an exabyte, and it's no problem. So these are some of the other ideas that this research touches.
Info-ZIP UnZip 6.0 mishandles the overlapping of files inside a ZIP container, leading to denial of service (resource consumption), aka a "better zip bomb" issue.
IMO this is not really a security problem with UnZip.
Debian merged a patch; SUSE decided not to. The Debian patch caused unanticipated problems with certain zip-like files:
So some of the outcomes of this zip—this kind of got a lot of attention online back at the beginning of July, and there was a CVE filed for Info-ZIP UnZip program, that command-line unzip program, saying it's capable of parsing these types of files. In my opinion, I have mixed feelings about this. I don't think this is really a security vulnerability in UnZip. I don't think it's a bug that UnZip can handle these types of files. Now, you may want prevent whatever system you're using from processing these types of files, but I don't think that's really the fault of UnZip, and for example, Debian decided to merge a patch that detects these types of files, and doesn't process them. SUSE decided not to. I think either is a defensible decision. I just depends on what your goals are. But it's worth noting that the Debian patch did break some legitimate zip files in the wild that happened to use overlapping files in some sort. That's how the detection works, it looks for these overlapping files. It's quite easy to do, but be aware that there are some actual zip files in the wild that have that characteristic.
VirusTotal for:
Selected web server referers:
This is kind of fun, here. You can click on the VirusTotal, more and more virus scanners, as this got attention, started detecting this as malware or started detecting it as some sort of compression bomb. And this is fun. These are referrers that hit my, a selection of referrers that hit the web page that I set up for this, and some of them you can see, there's a bunch of antivirus companies and firewall companies and things like this, so. When I made this, I thought, oh, this is not that interesting, you know, it's just a zip bomb. I did try it out on a few pieces of software to see if there's anything that's very obviously vulnerable, and by myself I didn't really find anything right away, so I thought, oh, you know, it's interesting but not really a big deal. But, you know, there are, I guess, a lot of these companies paying attention to this.
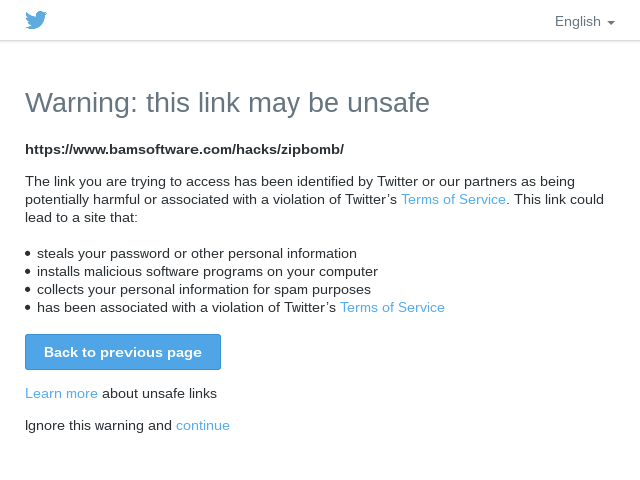

And another interesting side effect. A few days, actually it was about a month after the article had started to get some attention, Twitter started blocking links to my article, and then Google Safe Browsing started blocking links to my article. So if you click on these links at the top right now, you may get this scary page, depending on how you have your browser configured. And it's a little irritating, because they didn't just block this page, they blocked my entire domain and every subdomain, and like, broke some unrelated stuff that has nothing to do with the zip bomb article. Some, like, anti-censorship research I'm doing was on a subdomain of bamsoftware.com, and that was temporarily broken. So, I don't know, maybe I'll figure out some way to deal with that.
But anyway, it does add Google Safe Browsing to the list of esteemed things have blacklisted my web site. Number 1 being the Great Firewall of China, because I have a lot of anti-censorship research and things posted on my web site. But Number 2, welcome to the club, Google Safe Browsing.
https://www.bamsoftware.com/hacks/zipbomb/ (paper and code)
https://www.bamsoftware.com/talks/woot19-zipbomb/ (this talk)
And that's all I have for you today. Here are the links again. Thank you. [applause]
Alex Gantman: Thank you for a great talk. Do we have questions?
Question: Great work, really nice, creative, I like it. I have one nagging question. What is the practical value of this?
David Fifield: That's a good question. What is the practical value? To be honest, there is not a lot. This is more like a cool hack, and a means of increasing security awareness, as I see it, more than anything. There have been some practical proposals, for example using compression bombs—not necessarily zip bombs, but HTTP compression bombs—to deter web site crawlers, things like that. If something is following a link it should not, you could just feed them a ton of zeroes. If you are interested in doing that, the source code for the zip bomb has a nice constant-time DEFLATE compressor. So you don't actually have to gzip 10 gigabytes of zeroes, you can just do it in essentially constant time. So that may be useful if you're trying to do that. But really, I haven't found a lot of practical uses.
Alex Gantman: Other questions?
Question: So, do you see any possibility of changing the format to deter the—this?
David Fifield: That's a good question. Changing the format. Zip is so established—this is one of the hairy things about zip—it's so established, it's in everything. So many file formats. Android APKs are zip. Java JARs are zip. Microsoft Office documents are zip. There's so many implementations and the format is so old, I think it's beyond... I don't think there's any chance of changing the format. One thing you can do, is write, for example, a restricted parser, that may not recognize every valid zip file, but is designed to exclude obvious weird cases like this. And I think that is a kind of sound strategy. And really, one thing I think the world could really use, and if I had more time I would do it myself, is an independent specification of zip, separate from that APPNOTE.TXT I told you about, that would explain those corner cases, explain ambiguous cases, and be a new reference standard against which people could code their zip implementations that wouldn't have all these problems.
Question: And if I could, not so much a question but just an answer to that last question in terms of the practical use. I think it's a fabulous case study for educational purposes, for those that are going to follow us, in the context of building more secure, more resilient systems, to make a point about, writing better specifications, you know, that simple question that you should always ask in design: what could go wrong? And obviously was not asked. And, even to the point of the issue of data executing as code and all the inherent problems associated with that, things that the future developers will need to be aware of. And even the challenges of doing research in this space, that, you know, that Google themselves could potentially create problems. These are all really important things that the next generation of developers coming though our program should be made aware of. So thank you.
David Fifield: Yeah. That's right. And one of the things I always think about in computer security is, being a security practitioner, is partly about distinguishing what is apparent, and what is actual. What is the system apparently, or intentionally, designed to do, and what can it actually do? So the zip specification is an example of that. Reading that, you may have an idea of what a zip file looks like, but in fact, the specification allows for a lot of weird things such as this.
Alex Gantman: Right. I guess I have one more question. So you mentioned, David, that there are some, when people started scanning for it, they found some legitimate uses for it, legitimate uses in the wild. Have you looked at what those legitimate uses are?
David Fifield: Yeah. They are pretty easy to explain. The ones that I am aware of, these come from the Debian bug tracker, and bug report. One is that some JARs, and I think they were produced by a tool called Gradle, it does a weird thing where it will have multiple central directory headers—multiple table of contents—pointing to the same file, with the same filename. So really, it's just like, multiple copies of the same file, you know, pointing to the precise, exact header. And it seems have been a bug in Gradle, something unintentional, which has now been fixed, but you know, those JARs still exist out in the wild. And this Firefox one is a very weird case where they invented their own mutant zip-like structure that actually puts the central directory at the beginning—again, zip is flexible enough to allow weird things like this—but it confused the logic of this bomb detector.
Alex Gantman: All right. Let's thank David one more time. [applause]