Censorship model

David Fifield <david@bamsoftware.com>
"Internet censorship circumvention." What do we mean by that? Let's define some terms. This picture is what I always have in mind when I think about Internet censorship. There are a lot of other models that could go by that name, because they are instances of censorship and they involve the Internet, but the rest of the talk will only have to do with this model.
In this model, there's a client, and a destination, and a censor. The client resides within the censor's network, and the destination is outside. The censor controls all the network links inside its network, all the routers and ISPs, for example. In particular, the routers at the perimeter of the network. We give the censor a lot of power. It can block packets, replay them, inject new packets, etc. We don't really limit its computational ability, except that we assume it can't guess crypto keys. The client's goal is to send some message to the destination; we call this process "circumvention." It's like a game between the client and the censor: if the client circumvents, the client wins; if the censor prevents circumvention, the censor wins.
What's wrong with the model as I've described it? There's nothing to prevent the censor from winning trivially. Remember, the censor controls all the network links, so shutting down all communication is within its power, and that would certainly prevent circumvention. This missing ingredient is some kind of penalty, or cost, for the censor. The censor suffers some cost when it blocks something it shouldn't. There is, after all, a benefit to having Internet access. We're looking at this abstract model, but the costs we're talking about really are motivated by real-world costs. When the censor overblocks, it pays a price, for example if the censor is a country's government, then it may suffer a decrease in its citizens' productivity, or an increase in discontent. I'll give you an example: the government of China runs one of the most sophisticated censorship systems in the world, it's called the Great Firewall and it blocks tons of sites. The Great Firewall tried to block GitHub, the code-sharing site, presumably because GitHub was being used to host both forbidden information as well as circumvention software. GitHub was blocked for a time, but then the firewall backed off and unblocked it. Why? The general thinking is that it's too costly to block GitHub; the service is too valuable. I'm sure you've noticed whenever GitHub goes down, there's a storm on Twitter, nobody can get any work done. Furthermore, we see in practice that censors generally seem to want to minimize the amount of overblocking that they do. So a censor's goal is not just to block everything; it has to be selective in what it blocks.
Some typical censor behaviors are blocking traffic based on destination address, or blocking on the basis of the contents of packets, like keywords. I find it helpful to think of two kinds of blocking, blocking by content—i.e., what you say, keywords and so on—and blocking by address—who you're talking to, for example an IP address, a domain name, or an email address. The distinction between content and address isn't perfectly sharp, because we know network protocols are layered, and what's an address at one layer is content at another layer. Nevertheless, I find it helpful to think of blocking in this way. So if you're a censored client, how can you send a message with forbidden contents to a forbidden destination? Let's first deal with content blocking. For that, you can use encryption, assuming you and the destination have some key in common, you can encrypt the contents and the censor now can't scan for keywords. And as for address blocking, you can route through some third party whose address isn't blocked. (Generally we're always going to have to assume some cooperation with entities on the outside.) We'll call any such third-party host that facilitates circumvention a proxy. We'll use the word "proxy" very generically—it's not just the kind of proxy you may configure in your web browser, but it could also be some custom program running on someone's desktop, a VPN, or for instance like in Prof. Wustrow's research it could be a specialized network router.
In general, then, circumvention requires some kind of encrypted proxy. Encryption to prevent content blocking and a proxy to prevent address blocking. But now you have to worry about second-order censorship. First-order censorship is the direct blocking of the things the censor wants to block, like web sites and keywords. Second-order censorship means the censor additionally has to try to block proxies, because as we've seen, a proxy enables circumventing first-order censorship. It's here, with second-order censorship, that the field of research really begins. We're not so much concerned with reaching any arbitrary destination; we declare victory when we can reach a proxy, because then the proxy can connect us to anywhere. We posited an abstract encrypted proxy, but now the details matter. The encryption between the client and proxy, how does it work? If it uses a custom syntax, not used by anything else, then that's something the censor can detect and block. There are two basic ways of dealing with that problem. One is to imitate some other existing protocol, to cause the censor to misclassify the proxy communication as something else, like a video game, a chat program, or HTTP. The other is to completely randomize your protocol so that it doesn't match any of the censor's static protocol classifiers; this is the "look like nothing" approach, so called not because it literally looks like nothing, but because it looks like nothing specific. Why would this work? Couldn't the censor decide to block any weird, unidentifiable protocols? We observe empirically that censors tend not to do so; that they tend to employ blacklists and not whitelists. The usual explanation for why this is so is again the censor's sensitivity to cost and overblocking. Getting back to the challenges of second-order censorship, how do you prevent the censor from blocking the proxy's address? Say you've developed a circumvention system and you want people to use it. How do you give those people proxy addresses without also giving them to the censor? The censor can do anything a normal user can do, it can download your software and reverse engineer it, or simply run it and see what addresses it connects to, and then block those addresses. This particular problem, in my opinion, has not yet been satisfactorily solved. There have been several proposals, but no one has demonstrated one working in practice against a real censor.
Until a few years ago, the state of the art was essentially to have a large pool of proxies, and then be careful about how you distribute them, use some kind of rate-limiting to make it harder to discover and block all of them. For example, in Tor, there is a system for distributing bridges, which is Tor's term for circumvention proxies. (Tor is best known for anonymity, but it's also a focus of lots of censorship research, where is where I'm involved.) In Tor's bridge distribution system, you can go to a web page and ask for some bridges, and it will only give you three of them. If you ask again, you get the same three bridges. In order to discover more, you need to come from a different IP address. There is also an email autoresponder, same deal, as long as you ask from the same email address, you will get the same answer. The idea is that an adversary can't discover a lot of bridges without controlling a lot of resources, like IP addresses or email addresses. But real-world censors are often states, which can control lots of resources.
At was in about 2011 that there started to be alternatives to this many-proxies model. That was when Prof. Wustrow and others published designs for using network routers as proxies. The idea there is that if you block the proxy (router), you also block all the network destinations that lie beyond it, which goes against a censor's aversion to overblocking. I'm going to tell you about domain fronting, which is similar in spirit and removes the need for any secrecy about the identities of proxies. In order to understand domain fronting, we'll take a detour through the evolution of HTTPS—which is HTTP plus TLS—and see how the conditions arose that make domain fronting possible.
| without TLS | with TLS |
|---|---|
 |
 |
Go back to early HTTP, HTTP/1.0, circa 1995. It's a fairly simple protocol. The client sends a GET, and the name of the page it wants, and the server sends back a status code and the content.
To turn HTTP into HTTPS, you add a layer of TLS. The client initiates the handshake, and the server responds with the certificate for the one and only site that it hosts. After that, the HTTP exchange is unmodified, except that it happens underneath the TLS encryption and authentication. The layering is very clean, with no interaction between the layers.
| without TLS | with TLS |
|---|---|
 |
 |
One of the things that HTTP/1.1 added
was support for virtual hosting.
Virtual hosting is when one web server,
one IP address, serves several domains.
The server needs to know which domain the client intends;
the client communicates that using the
Host header.
How does TLS interact with virtual hosting? The client initiates the handshake as before, but now there's a problem—what certificate is the server supposed to send? The server has certificates for multiple domains and it needs to know which one to use. We have a chicken-and-egg problem: the client cannot send the Host header until the handshake is complete, but the handshake cannot complete without the server knowing the desired host.

SNI: Server Name Indication (TLS extension)
The resolution to the impasse was an extension to TLS, called SNI for "server name indication." It works simply by sending the desired domain name, in plaintext, as part of the client handshake. If you think that's a little weak, know that virtual hosting with HTTPS was a really pressing need at the time, and they needed to come up with some solution.
https://example.com/path
SNI solved the problem of HTTPS virtual hosting, which actually was an acute problem that needed a solution. But a consequence is that you leak your destination domain when you make an HTTPS connection, which means that HTTPS by itself helps with content blocking but not address blocking. When you browse to an HTTPS URL, an eavesdropper can tell a lot about it, for example the scheme (https://) and the domain name (because that's revealed in the SNI). It's a little disappointing to have what's supposed to be a secure protocol and it's leaking all this information. We'll return to this at the end of the talk.
Notice something peculiar in the HTTPS with SNI diagram. The domain "example.com" appears, redundantly, in two different places: the SNI and the Host header. This is an artifact of how HTTP and TLS have evolved together. If you were to design HTTPS from scratch today, it wouldn't work like this. But as it is, we have the same name in two places. What happens if the two names do not match?
$ wget -q -O - https://www.google.com/ --header "Host: www.android.com" | grep "<title>"
<title>Android</title>
$ curl -s https://www.google.com/ -H "Host: www.android.com" | grep "<title>"
<title>Android</title>
When the Host header and SNI do not match, we call it "domain fronting." What actually happens depends on the implementation. To start with, if the two names are not actually virtually hosted together, then it definitely will not work—you're likely to get an HTTP error saying your request is bad, host unknown. Another possible outcome is that even with virtual hosting, the server enforces a match. But another very common implementation choice means that you will get the certificate for the SNI name, but the actual page contents corresponding to the Host header name. And you can understand why a system might be implemented that way: maybe they have one host that terminates TLS, and then they do routing internally according to the Host header, it's a reasonable architecture. You can see how this is useful for circumvention: we can effectively access the destination given by the Host header, while appearing to the censor to be accessing the SNI server. The censor cannot distinguish the two cases, and so in order to block circumvention, it must also block whatever server is given by the SNI, which may be too costly. you can access one site (presumably blocked by the censor) while appearing to access another site (presumably unblocked). It really is indistinguishable from an ordinary non-fronted visit to the SNI domain, up to things like website fingerprinting. If the censor can only prevent circumvention by blocking access to the SNI domain. Why wouldn't the censor do that? Well, we can never be sure that it won't, but it again comes down to the costs associated with overblocking: ideally we find a front domain that is valuable enough that the censor doesn't want to block it.
Here's how you can try domain fronting in the command line. Somewhere there's a server that does virtual hosting for www.google.com and www.android.com (and a ton of other domains). If you construct an HTTPS request for www.google.com, but rewrite the Host header to say www.android.com, you actually get the contents of the Android page.

And virtual hosting is extremely common these days, in the form of CDNs (content delivery networks). A large fraction of web sites are hosted on some CDN or other. Domain fronting means that if we can find one domain on a CDN that the censor is unwilling to block, we can use it as a front to access any other domain hosted by the CDN. But actually we can do even better. In place of the blocked site, let's become a customer of the CDN and run a proxy on our own server. Now, the client can use domain fronting to reach our proxy, and our proxy can serve as the last mile towards whatever other destination the client may desire. This design, as implemented for Tor, is called "meek."
Audience question about cost: if you're sending all this traffic through a CDN, isn't it expensive? Answer: yes, it is, and it's one of the primary limitations of the approach. CDNs charge between $0.10 and $0.20 per gigabyte. In the early days of meek deployment, when I was watching the user graphs every day, I got excited the first time there was enough use to incur a charge. You see, we were running on Google App Engine, which gives you one gigabyte for free each day, and one day was the first day there had been more than one gigabyte of usage, costing a few cents. It got less exciting when the costs started to increase to hundreds and thousands of dollars per month. We had to rate-limit the proxy, in fact, to reduce usage, because we couldn't afford to let it run full throttle.
Note this difference between this system and the many-proxies model. There's no need to keep the proxy secret. The censor can know exactly what's going on, and still be reluctant to block because of the value of the fronted-through domain.
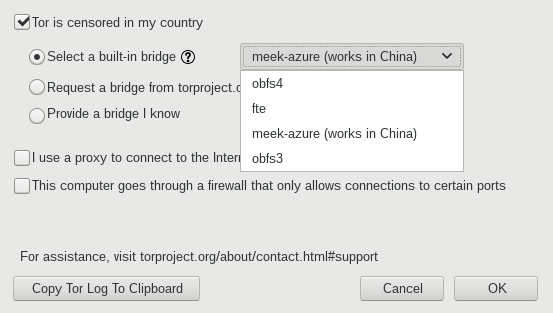
Here's a screenshot of how you would use this system in Tor Browser. In the configuration screen, there's an option for if you are censored, and you pick meek from the menu.
Domain fronting had a lot of success since 2014, in Tor and other systems. In this graph you see the average number of concurrent users of Tor with meek, around 10,000–20,000. This represents about 1% of all Tor users, and about a quarter to a third of Tor users who are using some form of circumvention. You'll notice a big drop in May 2018. That's the next topic.



Earlier history (2014–2017)
Domain fronting served us well for the past five years or so. About six months ago, though, things started to change. Amazon and Google announced that they would stop supporting domain fronting. There are some articles about it linked here. Tor wasn't actually using Google at the time, but it was using Amazon's CDN, which accounts for the halving of users. The rest of the users were going through Microsoft's CDN, called Azure, which for the time being still works. So domain fronting is still limping along, but there's a general feeling that we need something to take its place.
Audience question: what was the stated reason for blocking domain fronting? Amazon said they don't like that one customer's actions can cause harm (blocking) to another customer, which is a point of view I can sympathize with. Google said that an internal infrastructure change made it necessary. Whether these stated reasons are the real reason, I don't know. I suspect that it may be related to the attempted blocking of Telegram by the Russian government at around the same time period. The Russian firewall blocked over 10 million IP addresses belonging to Google and Amazon in an attempt to block Telegram. They eventually unblocked most of those addresses, and I have to imagine that it got their attention.
Audience question: your example earlier showed domain fronting on google.com, did they really shut it down? As far as I know, Google didn't actually stop domain fronting across all of their systems. They only blocked one specific destination, *.appspot.com, which is App Engine, which is a service that lets you run code such as a proxy on Google's servers. Domain fronting still works with most Google domains, just not the one that's most convenient to use for circumvention.
The good news is that there is now an IETF draft for SNI encryption, which is exactly what it sounds like. It's not part of the core TLS 1.3 standard, it will be an extension to TLS, just like SNI was. It works by distributing temporary SNI encryption keys through an out-of-band channel like DNS, which the client then uses to encrypt the SNI field. If encrypted SNI takes off—and I hope it does—it will solve all our current circumvention problems. Basically everything we can do today with domain fronting we'll be able to do with encrypted SNI, in a standards-based way that the cloud operators seem more happy with.
The draft standard if encrypted SNI is actually already deployed today. It's present on Cloudflare sites, and the client side is in nightly builds of Firefox. Audience question: any other implementations? Not that I know of.
I predict that encrypted SNI will force a change in the way that censors operate. Increasingly, censors are unable to to their work themselves; they have to reach out to network intermediaries and apply pressure on them. So we may see things like censors telling cloud companies, "we want you to drop this customer."